https://towardsdatascience.com/databases-an-overview-97c54628b824
Databases: An Overview
Part 2: Underlying Architecture of Distributed File Systems of MongoDB and HBase and Database Operations in Python
towardsdatascience.com
MongoDB
MongoDB is a document-based NoSQL database. It requires no fixed schema definition. Mongo DB stores data as Binary JSON or BSON. It supports horizontal scaling. Several servers instance group together as a cluster to support Mongo DB as a distributed system.
MongoDB uses MongoDB query language and supports Adhoc queries, Replication, and Sharding. Sharding is a feature of MongoDB that helps it to operate as a distributed data system. Let’s look at how MongoDB implements these features.
Replication in Mongo
Replication serves as a very important feature in order to protect data loss from one server, increase the availability of data, and give protection from failures.
MongoDB achieves replication using the concept replica sets. A replica set is a group of mongod instances that host the same data set. One of the nodes is selected as the primary or main node. This is called the primary node. All others are called secondary nodes. The primary node receives all the operations from the user and the secondaries are updated from the primary one by using the same operation to maintain consistency. If the primary node goes down, one of the secondary nodes is selected as the primary node and the operations are carried forward. When the fallen node recovers, it joins the cluster as the secondary nodes. We can control our cluster of mongo instances using Mongo Atlas. Mongo clusters are created based on the idea of horizontal scaling and adding of instances.
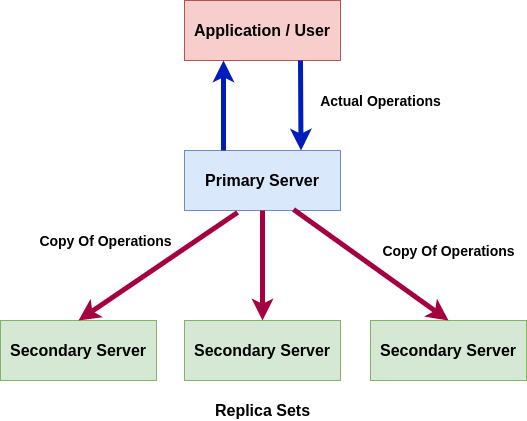
Replica set schematic: Image by Author
Sharding in Mongo DB
Sharding is used by MongoDB to store data across multiple machines. It uses horizontal scaling to add more machines to distribute data and operation with respect to the growth of load and demand.
Sharding arrangement in MongoDB has mainly three components:
- Shards or replica sets: Each shard serves as a separate replica set. They store all the data. They target to increase the consistency and availability of the data.
- Configuration Servers: They are like the managers of the clusters. These servers contain the cluster's metadata. They actually have the mapping of the cluster's data to the shards. When a query comes, query routers use these mappings from the config servers to target the required shard.
- Query Router: The query router is mongo instances which serve as interfaces for user applications. They take in the user queries from the applications and serve the applications with the required results. Usually, there are multiple query router per cluster for load distribution.
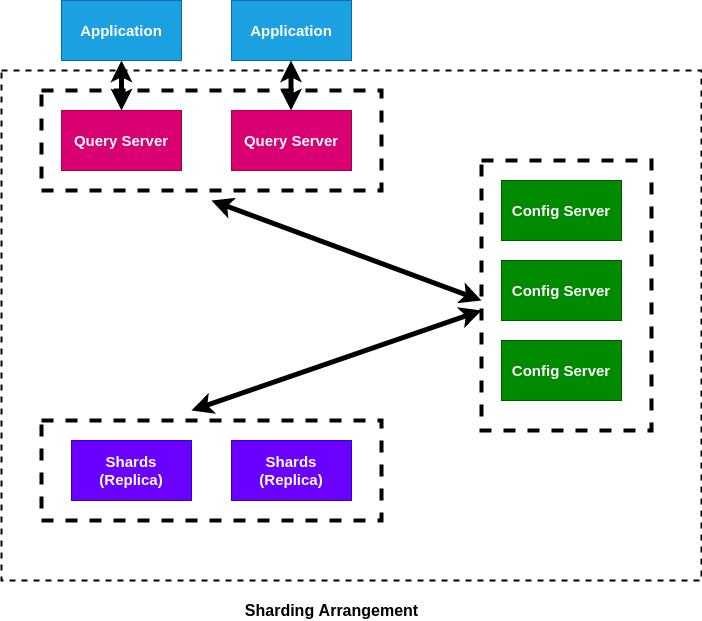
Image by author
The above image shows the sharding arrangement for MongoDB. Though the image has only 2 query servers and shards, generally there are more in an actual cluster, though by default case there are 3 config servers in a cluster.
The ideas we talked about above are the two most important ideas behind MongoDB operations and its distributed data system architecture.
Now, let’s take a look at how Apache HBase implements the ideas of distributed systems.
'emotional developer > detect-server' 카테고리의 다른 글
| How To Github Actions Local Test (0) | 2023.08.19 |
|---|---|
| Docker Architecture (0) | 2023.06.09 |
| The Architecture of Prometheus (0) | 2023.06.09 |

